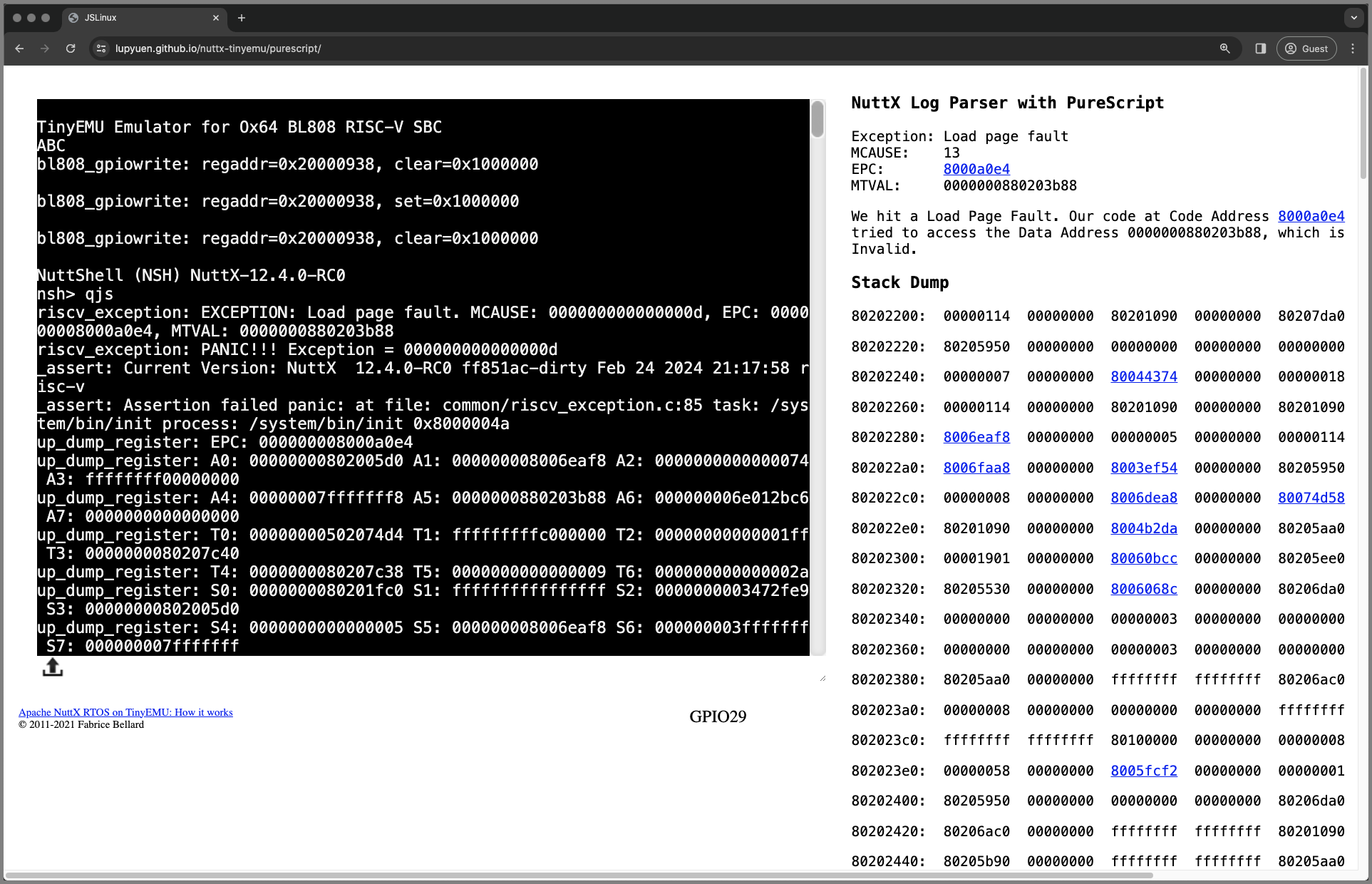
📝 3 Mar 2024
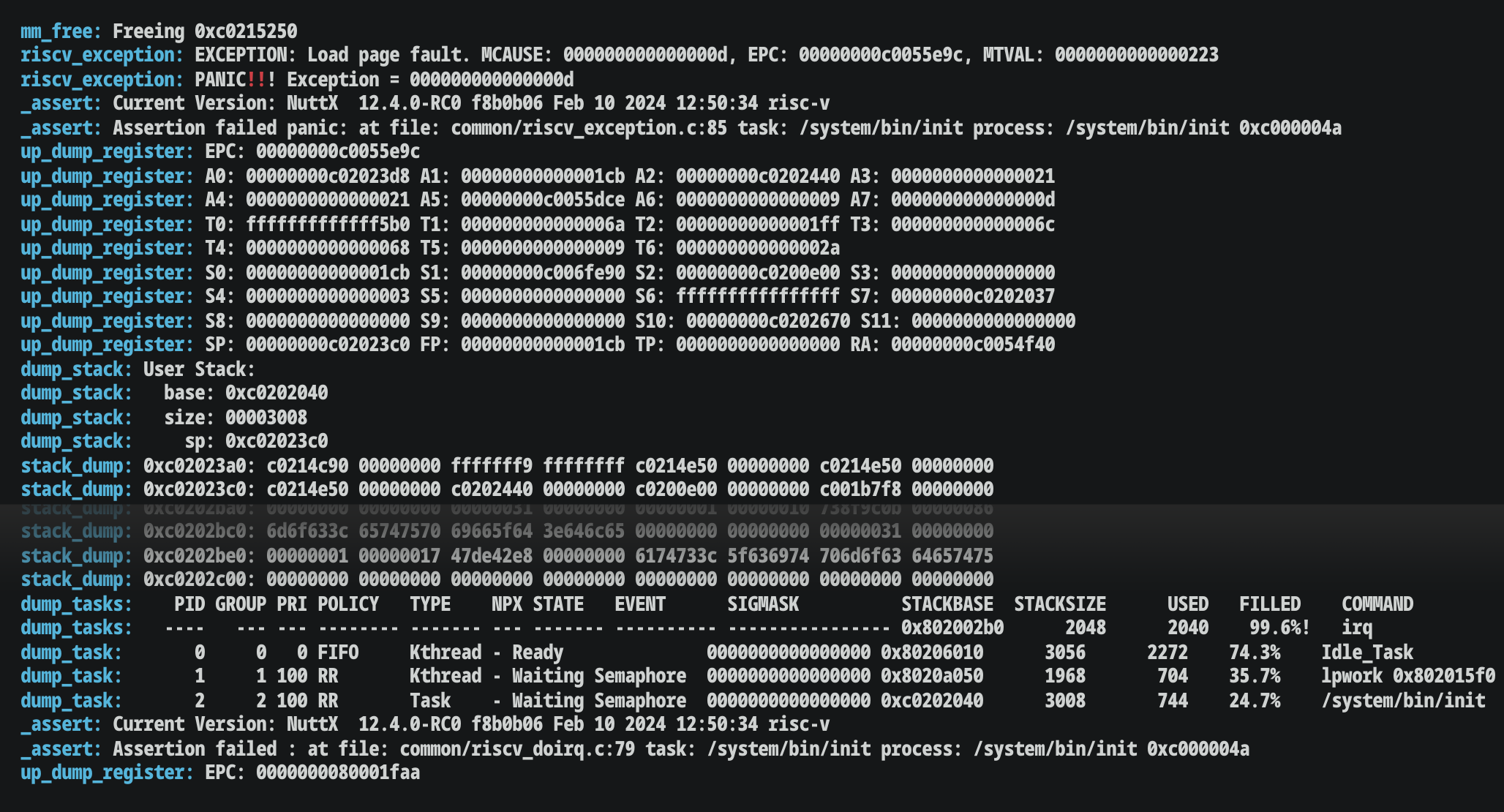
Over the Lunar New Year holidays, we were porting QuickJS to Ox64 BL808 SBC. And we hit a Baffling Crash Dump on Apache NuttX RTOS…
Which made us ponder…
Can we show the RISC-V Exception prominently?
(Without scrolling back pages and pages of logs)
(For folks new to RISC-V Exceptions)
Analyse the Stack Dump to point out Interesting Addresses
(For Code, Data, BSS, Heap, …)
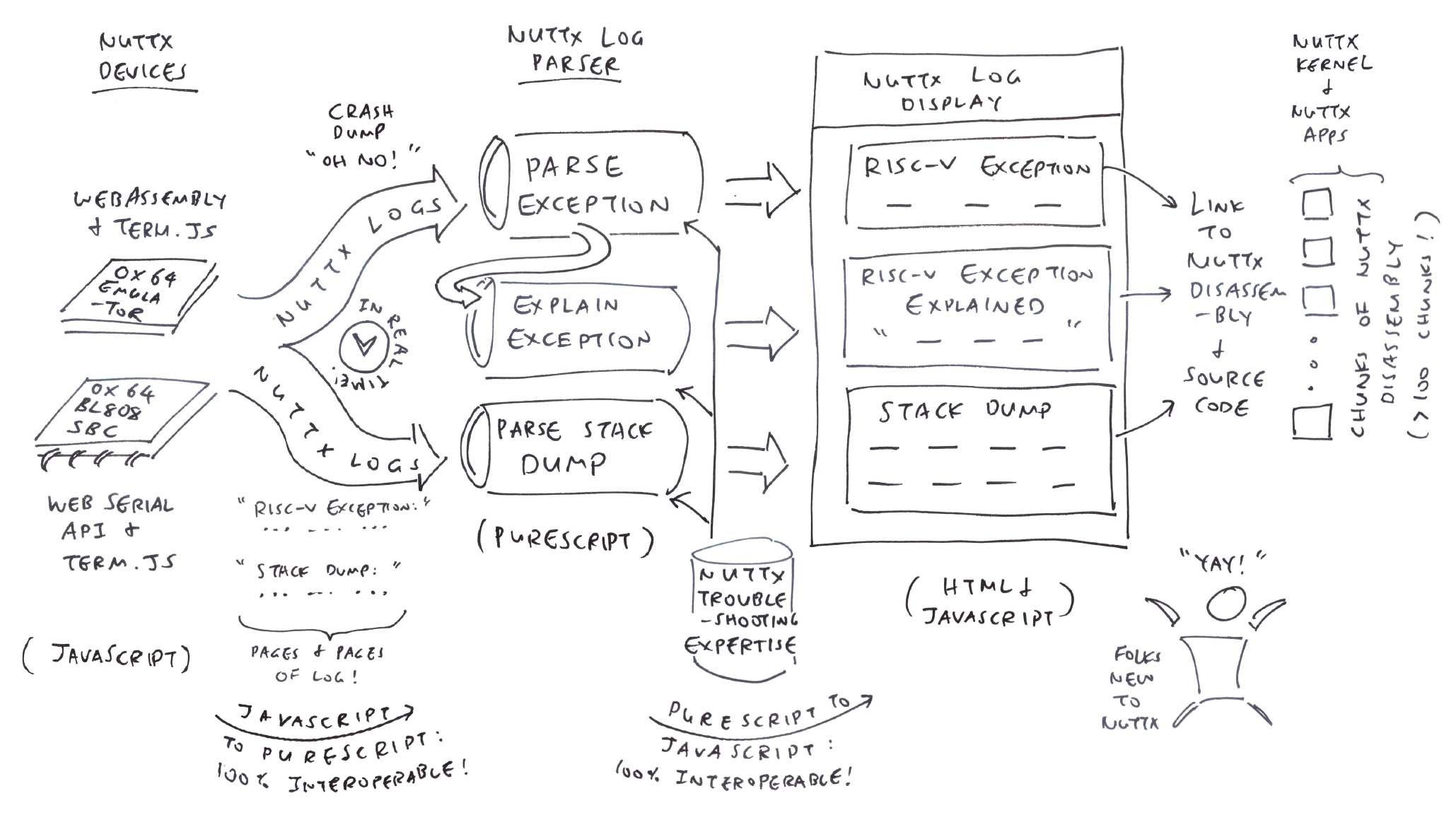
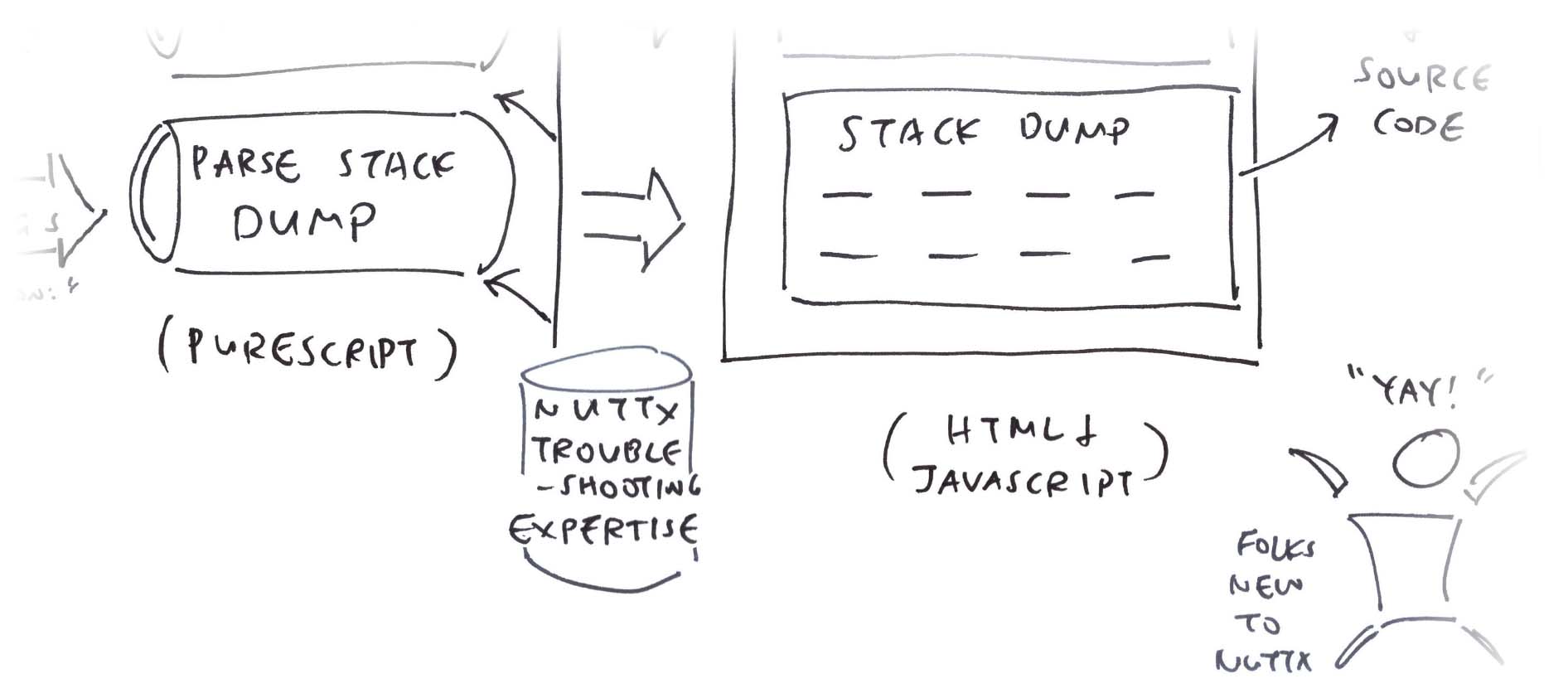
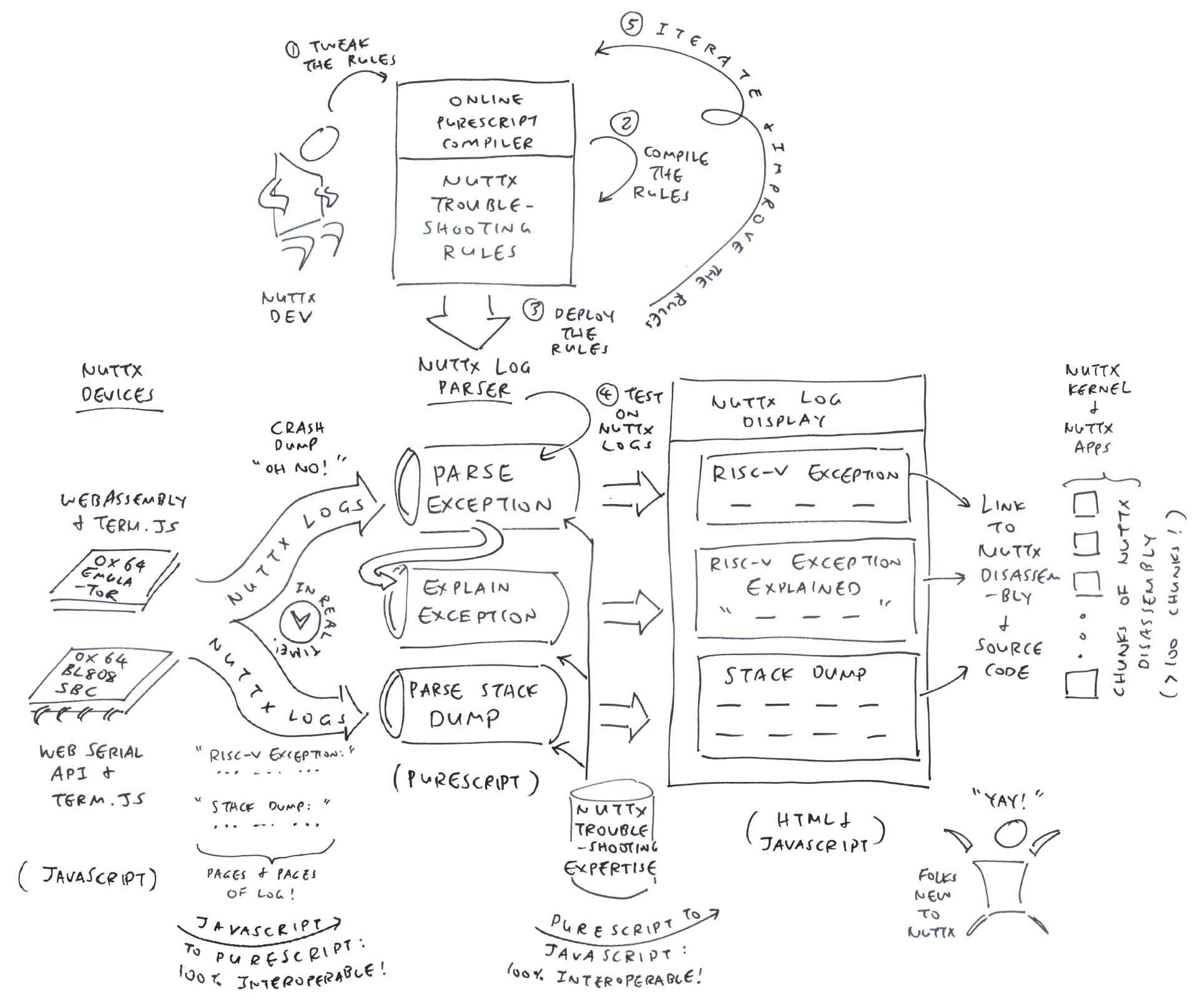
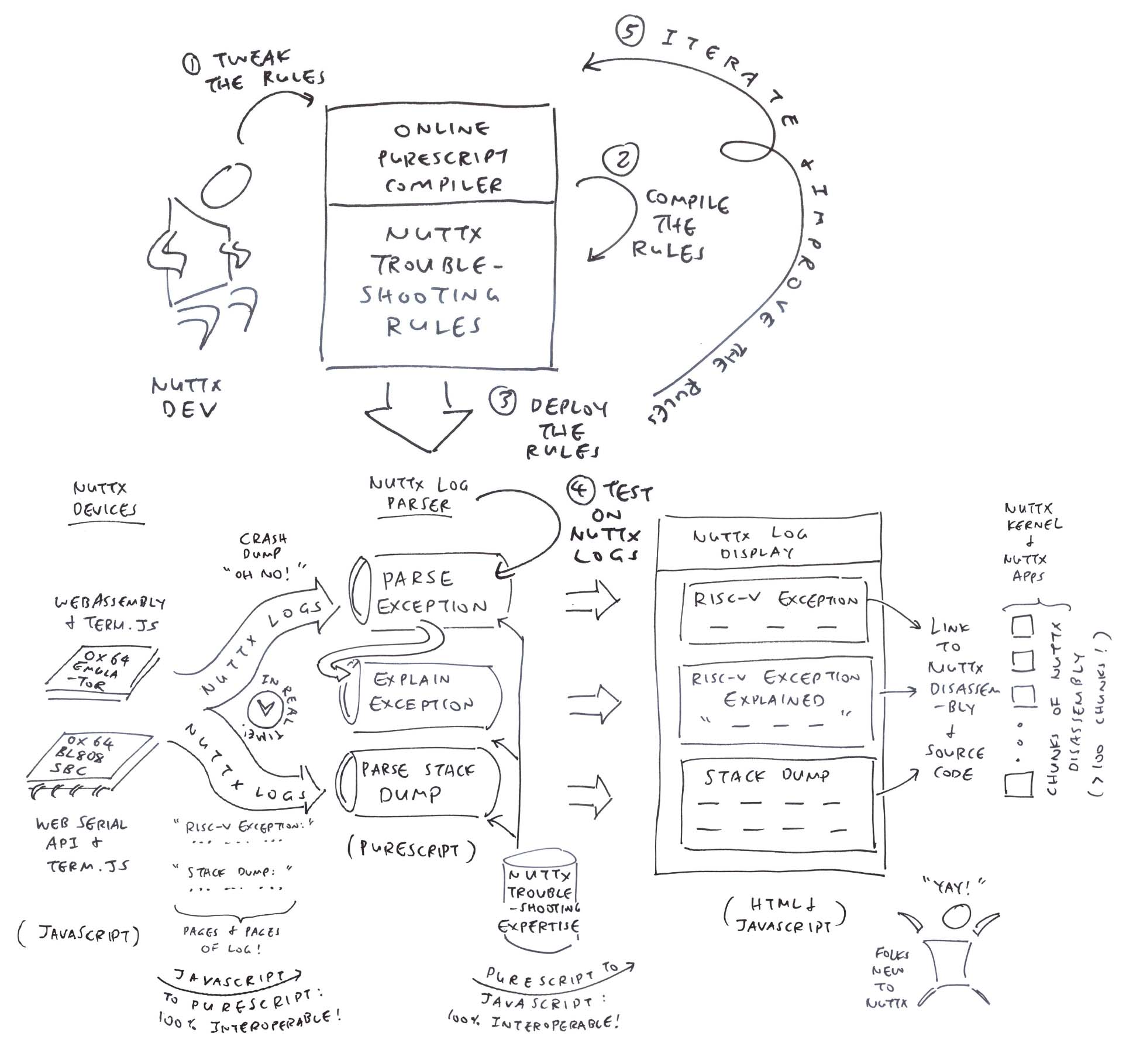
In this article, we create a NuttX Log Parser that will…
Extract the RISC-V Exception Details
Interpret and Explain the RISC-V Exception
Hyperlink the Stack Dump to NuttX Source Code and Disassembly
And we’ll do this in PureScript, the Functional Programming Language that compiles to JavaScript.
(We’ll see why in a moment)
To see our NuttX Log Parser in action, we run the NuttX Emulator in a Web Browser. (Pic above)
Inside the NuttX Emulator is the exact same NuttX App (QuickJS) that crashed over the holidays…
Head over to this link…
Apache NuttX RTOS boots on the Ox64 Emulator…
And starts our NuttX App: QuickJS
Our NuttX App crashes with a RISC-V Exception…
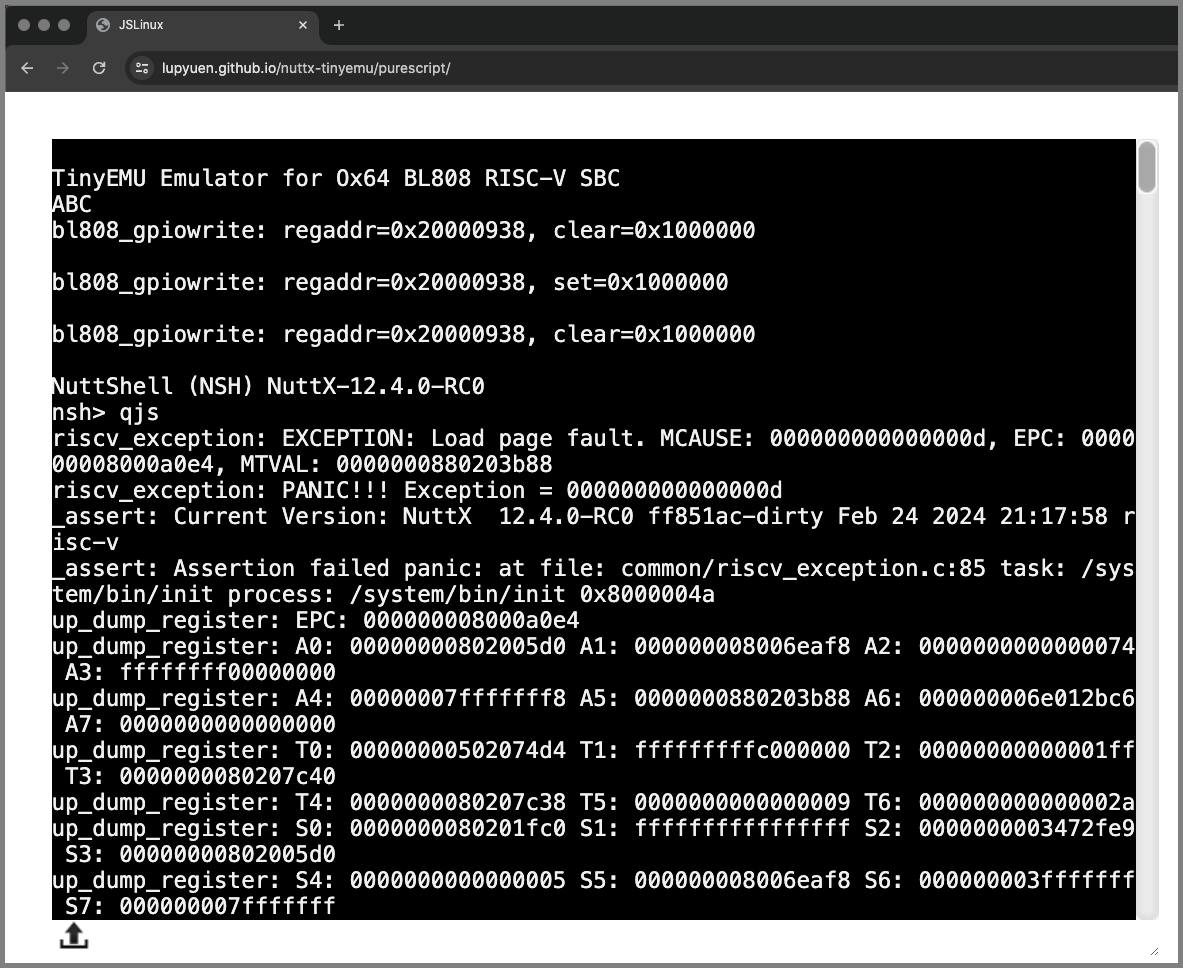
The Terminal Output at left shows pages and pages of logs.
(As seen by NuttX Devs today)
But something helpful appears at the right…
The NuttX Log Parser shows the RISC-V Exception Info
Followed by the Explanation of the Exception…

And the Stack Dump…

The NuttX Addresses are clickable.
Clicking an address brings us to the NuttX Disassembly
Which links to the NuttX Source Code. (Pic below)
What just happened?
Our NuttX App crashed on NuttX RTOS, producing tons of logs.
But thanks to the NuttX Log Parser, we extracted and interpreted the interesting bits: Exception Info, Exception Explanation and Stack Dump.
(With hyperlinks to NuttX Disassembly and Source Code)
How did we make it happen? We start with the smarty bits…
How did we explain the RISC-V Exception?
“We hit a Load Page Fault. Our code at Code Address 8000a0e4 tried to access the Data Address 880203b88, which is Invalid”
That’s our message that explains the RISC-V Exception…
MCAUSE 13: Cause of Exception
EPC 8000_A0E4: Exception Program Counter
MTVAL 8_8020_3B88: Exception Value
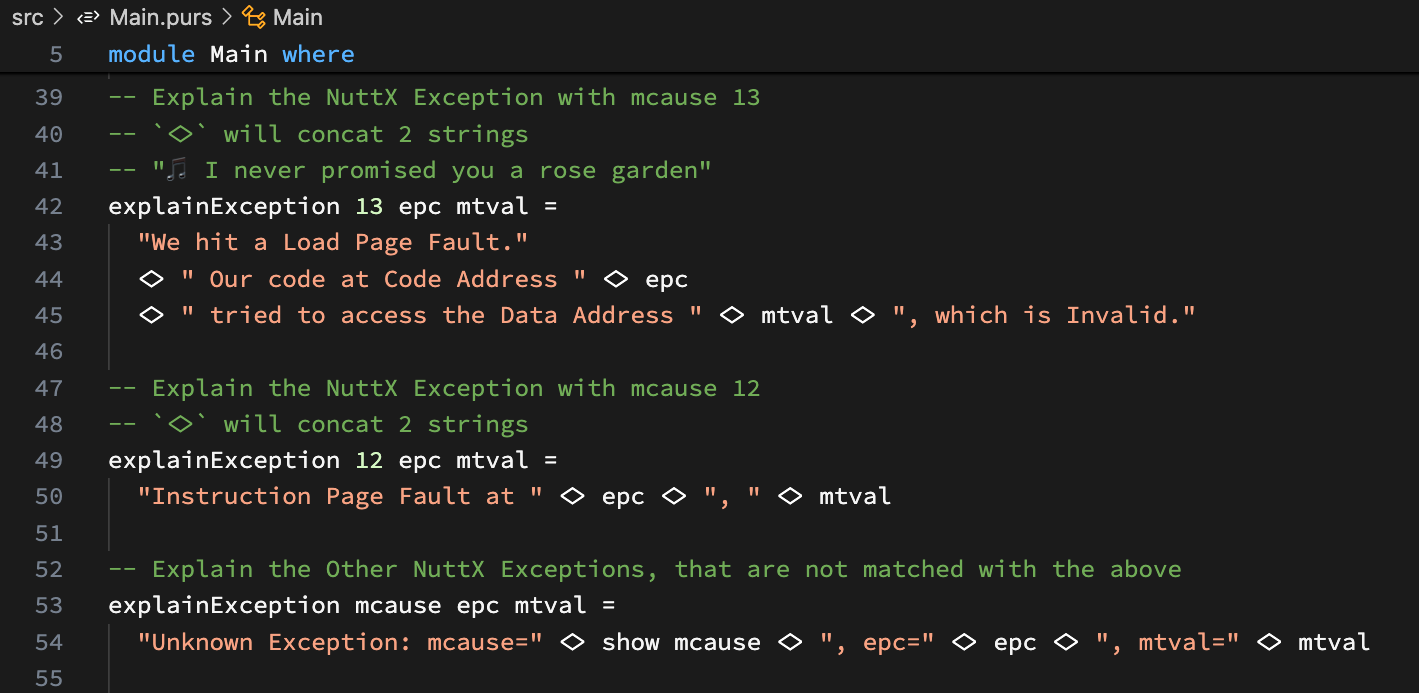
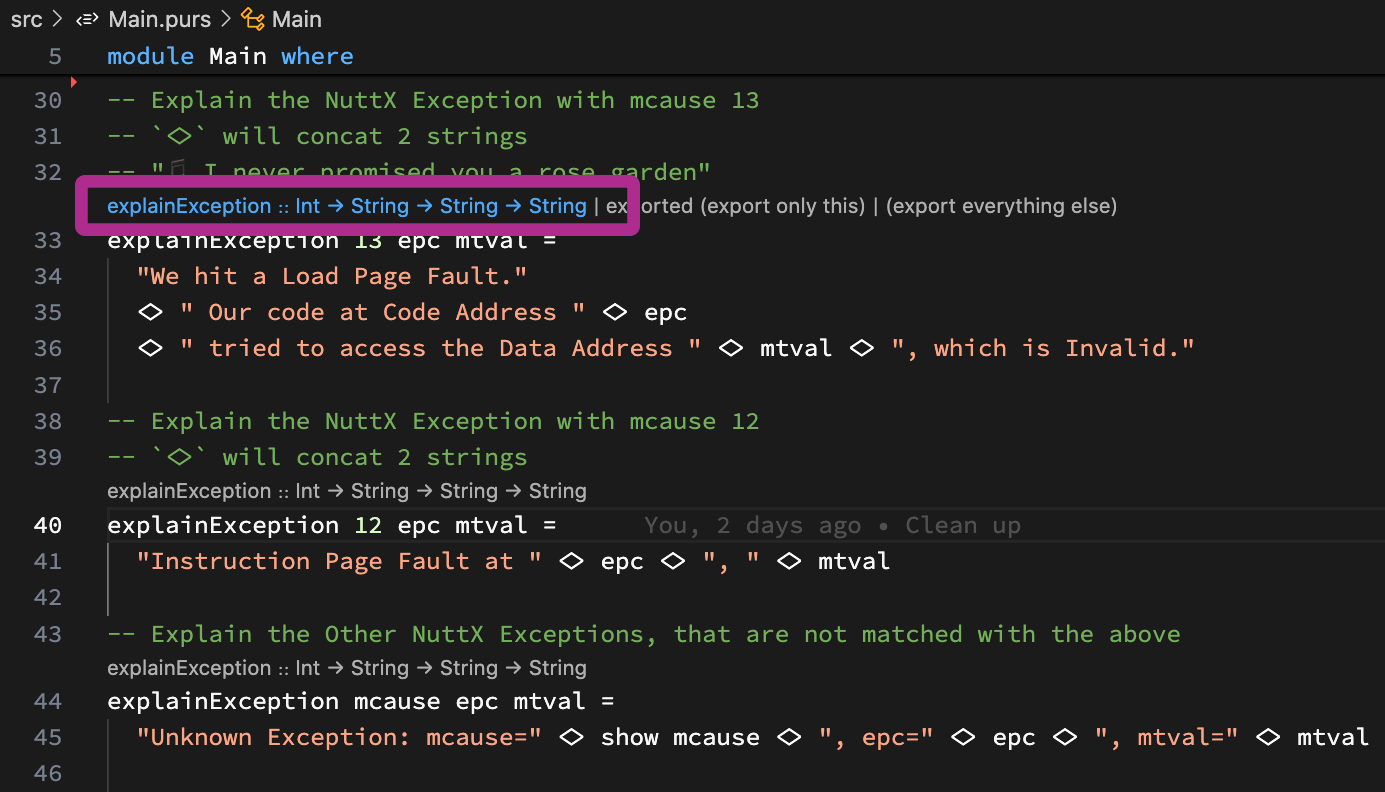
In PureScript: This is how we compose the helpful message: Main.purs
-- Explain the RISC-V Exception with mcause 13
-- `<>` will concat 2 strings
explainException 13 epc mtval =
"We hit a Load Page Fault."
<> " Our code at Code Address " <> epc
<> " tried to access the Data Address " <> mtval
<> ", which is Invalid."Hello Marvin the Martian?
Yeah we’ll meet some alien symbols in PureScript.
‘<>’ (Diamond Operator) will concatenate 2 strings.
We explain the other RISC-V Exceptions the same way: Main.purs
-- TODO: Explain the RISC-V Exception with mcause 12
-- `<>` will concat 2 strings
-- "🎵 I never promised you a rose garden"
explainException 12 epc mtval =
"Instruction Page Fault at " <> epc <> ", " <> mtval
-- TODO: Explain the Other RISC-V Exceptions,
-- that are not matched with the above.
-- `show` converts a Number to a String
explainException mcause epc mtval =
"Unknown Exception: mcause=" <> show mcause <> ", epc=" <> epc <> ", mtval=" <> mtvalWhich looks like a tidy bunch of Explain Rules. (Similar to Prolog!)
This thing about PureScript looks totally alien: Main.purs
-- Declare the Function Type.
-- We can actually erase it, VSCode PureScript Extension will helpfully suggest it for us.
explainException ::
Int -- MCAUSE: Cause of Exception
-> String -- EPC: Exception Program Counter
-> String -- MTVAL: Exception Value
-> String -- Returns the Exception ExplanationBut it works like a Function Declaration in C.
(VSCode will generate the declaration)
How will we call this from JavaScript?
Inside our Web Browser JavaScript, this is how we call PureScript: index.html
// In JavaScript: Import our PureScript Function
import { explainException } from './output/Main/index.js';
// Call PureScript via a Curried Function.
// Returns "Code Address 8000a0e4 failed to access Data Address 880203b88"
result = explainException(13)("8000a0e4")("880203b88");
// Instead of the normal non-spicy Uncurried Way:
// explainException(13, "8000a0e4", "880203b88")Our JavaScript will call PureScript the (yummy) Curried Way, because PureScript is a Functional Language.
Why PureScript? Could’ve done all this in JavaScript…
PureScript looks like a neat way to express our NuttX Troubleshooting Skills as high-level rules…
Without getting stuck with the low-level procedural plumbing of JavaScript.
Let’s do a bit more PureScript…
How did we get the RISC-V Exception? MCAUSE, EPC, MTVAL?
We auto-extracted the RISC-V Exception from the NuttX Log…
riscv_exception:
EXCEPTION: Load page fault.
MCAUSE: 000000000000000d,
EPC: 000000008000a0e4,
MTVAL: 0000000880203b88PureScript really shines for Parsing Text Strings. We walk through the steps: Main.purs
-- Declare our Function to Parse the RISC-V Exception
parseException :: Parser -- We're creating a Parser...
{ -- That accepts a String and returns...
exception :: String -- Exception: `Load page fault`
, mcause :: Int -- MCAUSE: 13
, epc :: String -- EPC: `8000a0e4`
, mtval :: String -- MTVAL: `0000000880203b88`
}(VSCode will generate the declaration)
We’re about to create a PureScript String Parser that will accept a printed RISC-V Exception and return the MCAUSE, EPC and MTVAL.
This is how we write our Parsing Function: Main.purs
-- To parse the line: `riscv_exception: EXCEPTION: Load page fault. MCAUSE: 000000000000000d, EPC: 000000008000a0e4, MTVAL: 0000000880203b88`
parseException = do
-- Skip `riscv_exception: EXCEPTION: `
void $
string "riscv_exception:" -- Match the string `riscv_exception:`
<* skipSpaces -- Skip the following spaces
<* string "EXCEPTION:" -- Match the string `EXCEPTION:`
<* skipSpaces -- Skip the following spacesAs promised, please meet our alien symbols…
void means ignore the text
(Similar to C)
$ something something
is shortcut for…
( something something )
<* is the Delimiter between Patterns
(Looks like an alien raygun)
Which will skip the unnecessary prelude…
riscv_exception: EXCEPTION: Next comes the Exception Message, which we’ll capture via a Regular Expression (and an alien raygun)
-- `exception` becomes `Load page fault`
-- `<*` says when we should stop the Text Capture
exception <- regex "[^.]+"
<* string "."
<* skipSpaces We do the same to capture MCAUSE (as a String)
-- Skip `MCAUSE: `
-- `void` means ignore the Text Captured
-- `$ something something` is shortcut for `( something something )`
-- `<*` is the Delimiter between Patterns
void $ string "MCAUSE:" <* skipSpaces
-- `mcauseStr` becomes `000000000000000d`
-- We'll convert to integer later
mcauseStr <- regex "[0-9a-f]+" <* string "," <* skipSpacesThen we capture EPC and MTVAL (with the Zero Prefix)
-- Skip `EPC: `
-- `epcWithPrefix` becomes `000000008000a0e4`
-- We'll strip the prefix `00000000` later
void $ string "EPC:" <* skipSpaces
epcWithPrefix <- regex "[0-9a-f]+" <* string "," <* skipSpaces
-- Skip `MTVAL: `
-- `mtvalWithPrefix` becomes `0000000880203b88`
-- We might strip the zero prefix later
void $ string "MTVAL:" <* skipSpaces
mtvalWithPrefix <- regex "[0-9a-f]+"Finally we return the parsed MCAUSE (as integer), EPC (without prefix), MTVAL (without prefix)
-- Return the parsed content.
-- `pure` because we're in a `do` block that allows (Side) Effects
-- TODO: Return a ParseError instead of -1
pure
{
exception
, mcause:
-1 `fromMaybe` -- If `mcauseStr` is not a valid hex, return -1
fromStringAs hexadecimal mcauseStr -- Else return the hex value of `mcauseStr`
, epc:
epcWithPrefix `fromMaybe` -- If `epcWithPrefix` does not have prefix `00000000`, return it
stripPrefix (Pattern "00000000") epcWithPrefix -- Else strip prefix `00000000` from `epc`
, mtval:
mtvalWithPrefix `fromMaybe` -- If `mtvalWithPrefix` does not have prefix `00000000`, return it
stripPrefix (Pattern "00000000") mtvalWithPrefix -- Else strip prefix `00000000` from `mtval`
}(fromMaybe resolves an Optional Value)
fromMaybe looks weird?
We tried to make our code “friendlier”…
a `fromMaybe` bIs actually equivalent to the Bracket Bonanza…
(fromMaybe a b)(Maybe we tried too hard)
Does it work with JavaScript?
Yep it does! This is how we parse a RISC-V Exception in JavaScript: index.html
// In JavaScript: Import our PureScript Parser
import { parseException } from './output/Main/index.js';
import * as StringParser_Parser from "./output/StringParser.Parser/index.js";
// We'll parse this RISC-V Exception
const exception = `riscv_exception: EXCEPTION: Load page fault. MCAUSE: 000000000000000d, EPC: 000000008000a0e4, MTVAL: 0000000880203b88`;
// Call PureScript to parse the RISC-V Exception
const result = StringParser_Parser
.runParser(parseException)(exception);Which returns the JSON Result…
{
"value0": {
"exception": "Load page fault",
"mcause": 13,
"epc": "8000a0e4",
"mtval": "0000000880203b88"
}
}And it works great with our RISC-V Exception Explainer!
// In JavaScript: Import our Exception Explainer from PureScript
import { explainException } from './output/Main/index.js';
// Fetch the Parsed RISC-V Exception from above
// TODO: If the parsing failed, then exception === undefined
const exception = result.value0;
// Explain the Parsed RISC-V Exception.
// Returns "We hit a Load Page Fault. Our code at Code Address 8000a0e4 tried to access the Data Address 0000000880203b88, which is Invalid."
const explain = explainException
(exception.mcause)
(exception.epc)
(exception.mtval);Let’s talk about log passing (and tossing)…

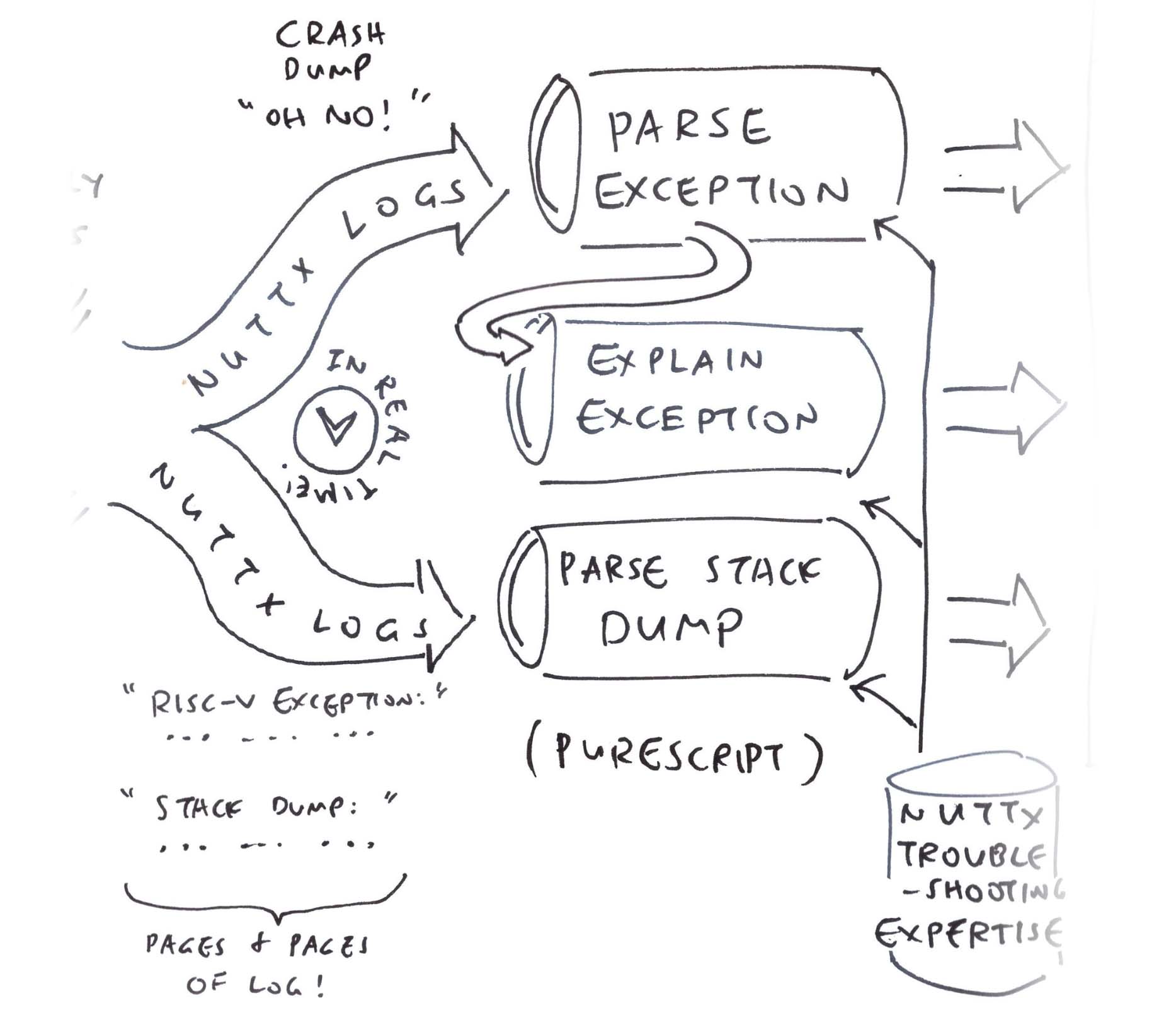
PureScript will parse our RISC-V Exceptions and explain them… How to pass our NuttX Logs to PureScript?
We’re running NuttX Emulator inside our Web Browser.
We intercept all logs emitted by the Emulator, with this JavaScript: term.js
// When NuttX Emulator prints something
// to the Terminal Output...
Term.prototype.write = function(ch) {
// Send it to our NuttX Log Parser
parseLog(ch);Our JavaScript parses NuttX Logs like this: term.js
// Parse NuttX Logs with PureScript.
// Assume `ch` is a single character for Terminal Output.
// PureScript Parser is inited in `index.html`
function parseLog(ch) {
// Omitted: Accumulate the characters into a line.
// Ignore Newlines and Carriage Returns
termbuf += ch;
...
// Parse the RISC-V Exception
// TODO: Check for exception.error === undefined
const exception = StringParser_Parser
.runParser(parseException)(termbuf)
.value0;
// Explain the Exception
const explain = explainException
(exception.mcause)
(exception.epc)
(exception.mtval);Line by line, we pass the NuttX Logs to PureScript, to parse the RISC-V Exceptions and explain them.
Then we display everything…
// Link the Exception to the Disassembly
const epc = disassemble(exception.epc);
const mtval = disassemble(exception.mtval);
const exception_str = [
"Exception:" + exception.exception,
"MCAUSE:" + exception.mcause,
"EPC:" + epc,
"MTVAL:" + mtval,
].join("<br>");
// Display the Exception
const parser_output = document.getElementById("parser_output");
parser_output.innerHTML +=
`<p>${exception_str}</p>`;
// Display the Exception Explanation
parser_output.innerHTML +=
`<p>${explain}</p>`
.split(exception.epc, 2).join(epc) // Link EPC to Disassembly
.split(exception.mtval, 2).join(mtval); // Link MTVAL to Disassembly(We’ll see disassemble later)
We do the same for the Stack Dump…
// Parse the Stack Dump and link to the Disassembly
// TODO: Check for stackDump.error === undefined
const stackDump = StringParser_Parser
.runParser(parseStackDump)(termbuf)
.value0;
// Display the Stack Dump
const str = [
stackDump.addr + ":",
disassemble(stackDump.v1), disassemble(stackDump.v2), disassemble(stackDump.v3), disassemble(stackDump.v4),
disassemble(stackDump.v5), disassemble(stackDump.v6), disassemble(stackDump.v7), disassemble(stackDump.v8),
].join(" ");
parser_output.innerHTML +=
`<p>${str}</p>`;
// Reset the Line Buffer
termbuf = "";
}
// Buffer the last line of the Terminal Output
let termbuf = "";Will this work for a Real NuttX Device?
NuttX on Ox64 BL808 SBC runs in a Web Browser with Web Serial API and Term.js.
We’ll intercept and parse the NuttX Logs in Term.js, the exact same way as above.
What’s this function: disassemble?
Instead of printing addresses plainly like 8000a0e4, we show Addresses as Hyperlinks…
<a href="disassemble.html?addr=8000a0e4" target="_blank">
8000a0e4
</a>Which links to our page that displays the NuttX Disassembly for the address: term.js
// If `addr` is a valid address,
// wrap it with the Disassembly URL:
// <a href="disassemble.html?addr=8000a0e4" target="_blank">8000a0e4</a>
// Otherwise return `addr`
function disassemble(addr) {
// If this is an Unknown Address:
// Return it without hyperlink
const id = identifyAddress(addr).value0;
if (id === undefined) { return addr; }
// Yep `addr` is a valid address.
// Wrap it with the Disassembly URL
const url = `disassemble.html?addr=${addr}`;
return [
`<a href="${url}" target="_blank">`,
addr,
`</a>`,
].join("");
}But we do this only for Valid NuttX Addresses. (Otherwise we’ll hyperlink to hot garbage)
How will identifyAddress know if it’s a Valid NuttX Address? Coming right up…
Given a NuttX Address like 8000a0e4: How will we know if it’s in NuttX Kernel or NuttX App? And whether it’s Code, Data, BSS or Heap?
Once Again: We get a little help from PureScript to match the Regex Patterns of Valid NuttX Addresses: Main.purs
-- Given an Address: Identify the
-- Origin (NuttX Kernel or App) and
-- Type (Code / Data / BSS / Heap)
identifyAddress addr
-- `|` works like `if ... else if`
-- "a `matches` b" is same as "(matches a b)"
-- `Just` returns an OK Value. `Nothing` returns No Value.
-- Address 502xxxxx comes from NuttX Kernel Code
| "502....." `matches` addr =
Just { origin: "nuttx", type: Code }
-- Address 800xxxxx comes from NuttX App Code (QuickJS)
| "800....." `matches` addr =
Just { origin: "qjs", type: Code }
-- Otherwise it's an Unknown Address
| otherwise = NothingHow does it work?
The code above is called by our JavaScript to Identify NuttX Addresses: index.html
// In JavaScript: Call PureScript to Identify a NuttX Address.
import { identifyAddress } from './output/Main/index.js';
// For NuttX Kernel Address:
// Returns {value0: {origin: "nuttx", type: {}}
result = identifyAddress("502198ac");
// For NuttX App Address:
// Returns {value0: {origin: "qjs", type: {}}
result = identifyAddress("8000a0e4");
// Why is the `type` empty? That's because it's a
// JavaScript Object that needs extra inspection.
// This will return "Code" or "Data" or "BSS" or "Heap"...
addressType = result.value0.type.constructor.name;
// Unknown Address returns {}
result = identifyAddress("0000000800203b88");
// This will return "Nothing"
resultType = result.constructor.name;Tsk tsk we’re hard-coding Address Patterns?
Our Troubleshooting Rules are still evolving, we’re not sure how the NuttX Log Parser will be used in future.
That’s why we’ll have an Online PureScript Compiler that will allow the Troubleshooting Rules to be tweaked and tested easily across all NuttX Platforms.
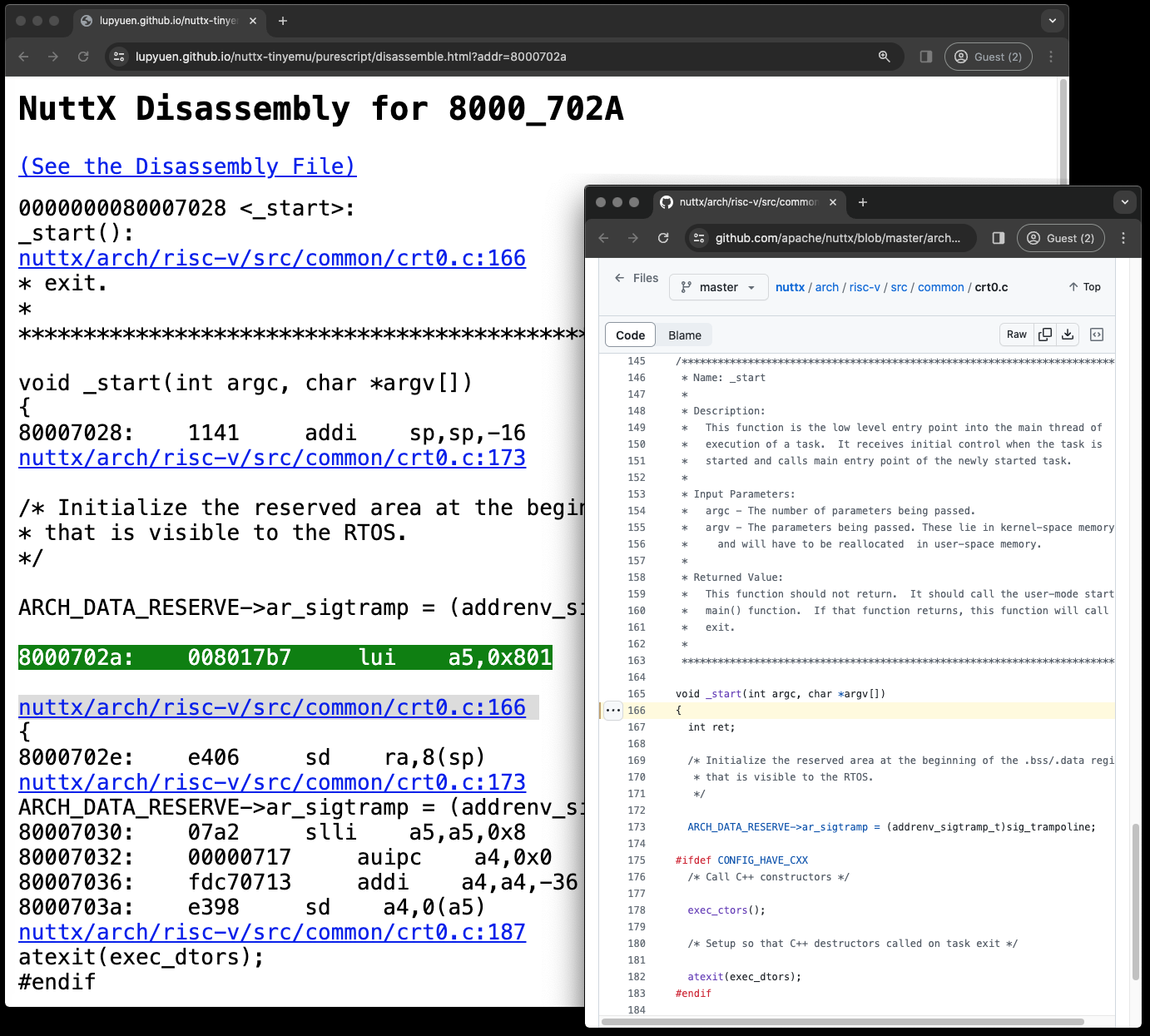
NuttX Disassembly for 8000_702A
Given a NuttX Address like 8000a0e4: How shall we show the NuttX Disassembly?
We chunked up the NuttX Disassembly into many many small files (by NuttX Address)…
## NuttX App Dissassembly (QuickJS)
## Chunked into 101 small files
$ ls nuttx-tinyemu/docs/purescript/qjs-chunk
qjs-80001000.S
qjs-80002000.S
...
qjs-80063000.S
qjs-80064000.S
qjs-80065000.SSo 8000a0e4 will appear in the file qjs-8000b000.S
// NuttX Disassembly for 8000a0e4
quickjs-nuttx/quickjs.c:2876
p = rt->atom_array[i];
8000a0e4: 6380 ld s0,0(a5)Which gets hyperlinked in our NuttX Log Display whenever 8000a0e4 is shown…
<a href="disassemble.html?addr=8000a0e4" target="_blank">
8000a0e4
</a>What’s inside disassemble.html? (Pic above)
Given a NuttX Address like 8000a0e4…
disassemble.html?addr=8000a0e4disassemble.html will…
Fetch the Disassembly Chunk File: qjs-8000b000.S
Search for address 8000a0e4 in the file
Display 20 lines of NuttX Disassembly before and after the address
Hyperlink to the NuttX Source Code…
<a href="https://github.com/lupyuen/quickjs-nuttx/blob/master/quickjs.c#L2877" target="_blank">
quickjs-nuttx/quickjs.c:2877
</a>How do we chunk a NuttX Dissassembly?
We created a NuttX Disassembly Chunker that will…
Split a huge NuttX Disassembly: qjs.S
Into smaller Disassembly Chunk Files: qjs-chunk/qjs-80001000.S
So that Disassembly Address 0x8000_0000 goes into qjs-80001000.S
And Disassembly Address 0x8000_1000 goes into qjs-80002000.S, …
We run the chunker like this…
## Dump the NuttX Disassembly
## for NuttX ELF qjs
riscv64-unknown-elf-objdump \
-t -S --demangle --line-numbers --wide \
$HOME/qjs \
>$HOME/qjs.S \
2>&1
## Chunk the NuttX Disassembly
## at $HOME/qjs.S into
## $HOME/qjs-chunk/qjs-80001000.S
## $HOME/qjs-chunk/qjs-80002000.S
## ...
chunkpath=$HOME
chunkbase=qjs
mkdir -p $chunkpath/$chunkbase-chunk
rm -f $chunkpath/$chunkbase-chunk/*
## Run the NuttX Disassembly Chunker
## TODO: Edit the pathnames in https://github.com/lupyuen/nuttx-disassembly-chunker/blob/main/src/main.rs#L81-L91
git clone https://github.com/lupyuen/nuttx-disassembly-chunker
cd nuttx-disassembly-chunker
cargo run -- $chunkpath $chunkbaseSo what exactly caused our NuttX Crash Dump over the holidays? And made us ponder our life choices?
Our NuttX Stack was Full! There was a clear sign that we missed: The Loopy Stack Dump means that the NuttX Stack was obviously full.
That’s why we need a Smarter Log Parser that will catch these common problems. And stop NuttX Devs from falling into traps!
Troubleshooting NuttX Crash Dumps will become a little less painful… Thanks to our new NuttX Log Parser!
We auto-extracted the RISC-V Exception Details
Interpreted and Explained the RISC-V Exception
While hyperlinking the Stack Dump to NuttX Source Code and Disassembly
Though we still need to Codify our NuttX Expertise as Troubleshooting Rules
PureScript might make it easier to capture our skills across NuttX Platforms
Many Thanks to my GitHub Sponsors (and the awesome NuttX Community) for supporting my work! This article wouldn’t have been possible without your support.
Got a question, comment or suggestion? Create an Issue or submit a Pull Request here…
lupyuen.github.io/src/purescript.md
If we wish to update the NuttX Log Parser in PureScript: This is how we download and build the code…
## Download the NuttX Log Parser in PureScript
git clone https://github.com/lupyuen/nuttx-purescript-parser
cd nuttx-purescript-parser
## Edit our code in `src/Main.purs`
code .
## Build and Run the NuttX Log Parser
spago run
## Deploy to GitHub Pages in `docs` folder
## https://lupyuen.github.io/nuttx-purescript-parser/
./run.sh“spago run” will compile our NuttX Log Parser and generate…
run.sh will rewrite the JavaScript Imports. (See the next section)
Remember to install the PureScript IDE VSCode Extension. It will auto-generate the Function Types when we click on the Suggested Type…
From the previous section, PureScript Compiler “spago run” generates the JavaScript for our NuttX Log Parser at…
Which means we need to deploy the Other JavaScript Modules. But there’s a workaround…
Here’s how we rewrite the JavaScript (generated by PureScript Compiler), so it points the JavaScript Imports to compile.purescript.org: run.sh
## Change:
## import { ... } from './output/Main/index.js';
## To:
## import { ... } from './index.js';
## Change:
## import * as StringParser_Parser from "./output/StringParser.Parser/index.js";
## To:
## import * as StringParser_Parser from "https://compile.purescript.org/output/StringParser.Parser/index.js";
cat index.html \
| sed 's/output\/Main\///' \
| sed 's/.\/output\//https:\/\/compile.purescript.org\/output\//' \
>docs/index.html
## Change:
## import * as Control_Alt from "../Control.Alt/index.js";
## To:
## import * as Control_Alt from "https://compile.purescript.org/output/Control.Alt/index.js";
cat output/Main/index.js \
| sed 's/from \"../from \"https:\/\/compile.purescript.org\/output/' \
>docs/index.js(index.html is our Test JavaScript)
This produces the Modified JavaScript: docs/index.js
Which gets published at nuttx-purescript-parser/index.js
How is this JavaScript imported by NuttX Emulator?
NuttX Emulator imports the Modified JavaScript for NuttX Log Parser like this: index.html
<script type=module>
// Import the NuttX Log Parser
import { parseException, parseStackDump, explainException, identifyAddress }
from 'https://lupyuen.github.io/nuttx-purescript-parser/index.js';
import * as StringParser_Parser
from "https://compile.purescript.org/output/StringParser.Parser/index.js";
// Allow other modules to call the PureScript Functions
window.StringParser_Parser = StringParser_Parser;
window.parseException = parseException;
window.parseStackDump = parseStackDump;
window.explainException = explainException;
window.identifyAddress = identifyAddress;
// Call the PureScript Function
const result2 = explainException(12)('000000008000ad8a')('000000008000ad8a')Why are we passing addresses in Text instead of Numbers? Like "8000ad8a"
That’s because 0x8000ad8a is too big for PureScript Int, a signed 32-bit integer.
PureScript Int is meant to interoperate with JavaScript Integer, which is also 32-bit.
What about PureScript BigInt?
spago install bigints
npm install big-integerIf we use PureScript BigInt, then we need NPM big-integer.
But NPM big-integer won’t run inside a Web Browser with Plain Old JavaScript. That’s why we’re passing addresses as Strings instead of Numbers.
TODO: BigInt is already supported by Web Browsers. Do we really need NPM big-integer?
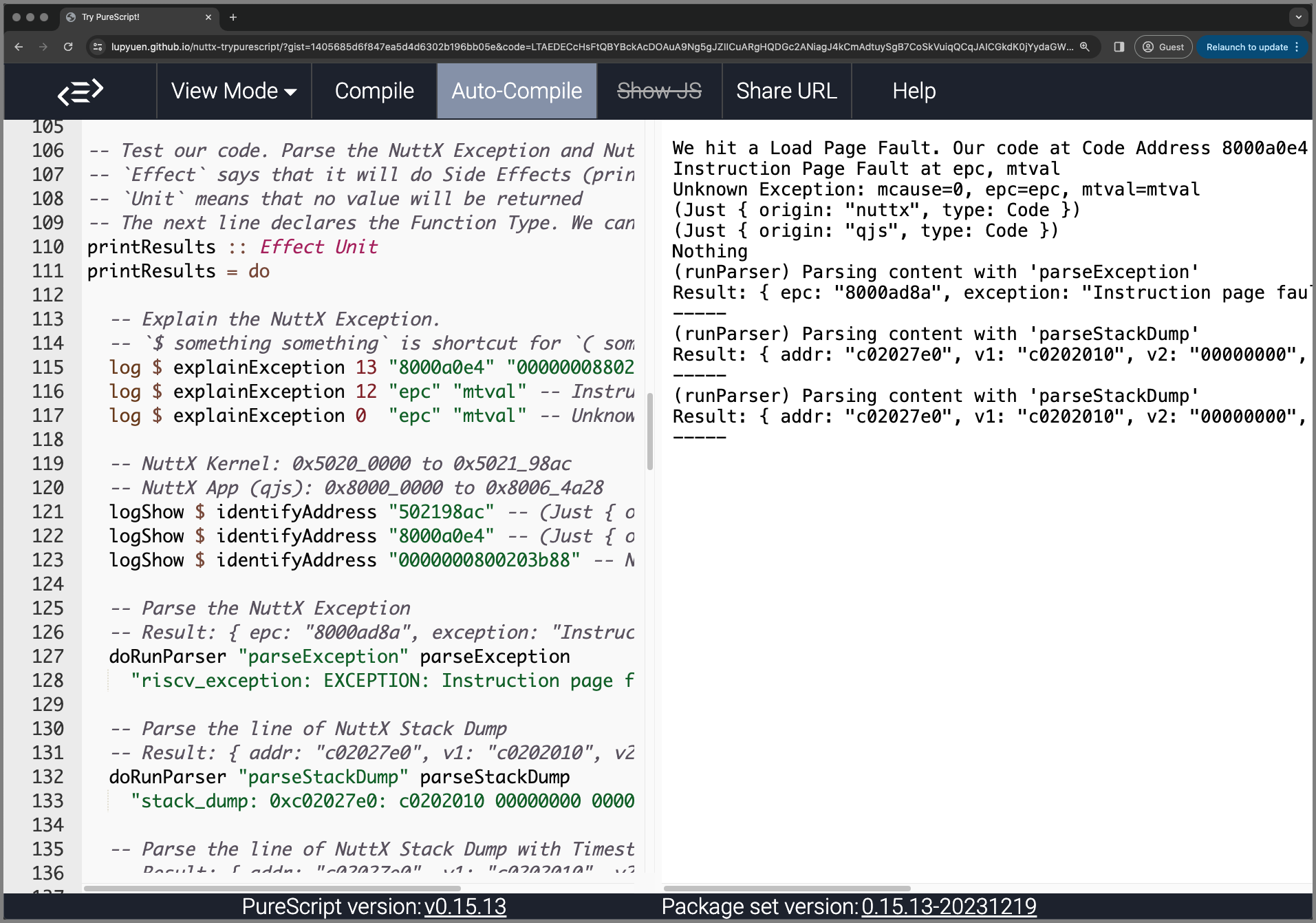
Try the Online PureScript Compiler
How will we allow the NuttX Troubleshooting Rules to be tweaked and tested easily across all NuttX Platforms?
The Online PureScript Compiler will let us modify and test the NuttX Troubleshooting Rules in a Web Browser (pic above)…
Head over to our Online PureScript Compiler
Which compiles our NuttX Log Parser (from PureScript to JavaScript)
Our NuttX Log Parser runs in the Web Browser…
We hit a Load Page Fault. Our code at Code Address 8000a0e4 tried to access the Data Address 0000000880203b88, which is Invalid.
Instruction Page Fault at epc, mtval
Unknown Exception: mcause=0, epc=epc, mtval=mtval
(Just { origin: "nuttx", type: Code })
(Just { origin: "qjs", type: Code })
Nothing
(runParser) Parsing content with 'parseException'
Result: { epc: "8000ad8a", exception: "Instruction page fault", mcause: 12, mtval: "8000ad8a" }
-----
(runParser) Parsing content with 'parseStackDump'
Result: { addr: "c02027e0", v1: "c0202010", v2: "00000000", v3: "00000001", v4: "00000000", v5: "00000000", v6: "00000000", v7: "8000ad8a", v8: "00000000" }
-----
(runParser) Parsing content with 'parseStackDump'
Result: { addr: "c02027e0", v1: "c0202010", v2: "00000000", v3: "00000001", v4: "00000000", v5: "00000000", v6: "00000000", v7: "8000ad8a", v8: "00000000" }
-----Try tweaking the rules for explainException…
explainException 13 epc mtval =
"We hit a Load Page Fault."
<> " Our code at Code Address " <> epc
<> " tried to access the Data Address " <> mtval
<> ", which is Invalid."And identifyAddress…
identifyAddress addr
| "502....." `matches` addr = Just { origin: "nuttx", type: Code }
| "800....." `matches` addr = Just { origin: "qjs", type: Code }
| otherwise = NothingThe changes will take effect immediately.
Future Plans: We’ll copy the Generated JavaScript to NuttX Emulator via JavaScript Local Storage.
So we can test our Modified NuttX Log Parser on the Actual NuttX Logs.
The PureScript Compiler Web Service is super helpful for compiling our PureScript Code to JavaScript, inside our Web Browser.
If we wish to run the Online PureScript Compiler locally on our computer…
## Download the Online PureScript Compiler
git clone https://github.com/lupyuen/nuttx-trypurescript
cd nuttx-trypurescript
cd client
## To Build and Test Locally:
## This produces `output` folder
## and `public/js/index.js`
## Test at http://127.0.0.1:8080?gist=1405685d6f847ea5d4d6302b196bb05e
npm install
npm run serve:production
## To Deploy to GitHub Pages in `docs` folder:
rm -r ../docs
cp -r public ../docs
## To Test Locally the GitHub Pages in `docs` folder:
## http://0.0.0.0:8000/docs/index.html?gist=1405685d6f847ea5d4d6302b196bb05e
cargo install simple-http-server
simple-http-server .. &The Test Code comes from our GitHub Gist.